When checked, my code is incorrect - can you please provide the
correct code?
- When Checked My Code Is Incorrect Can You Please Provide The Correct Code 1 (100.43 KiB) Viewed 21 times
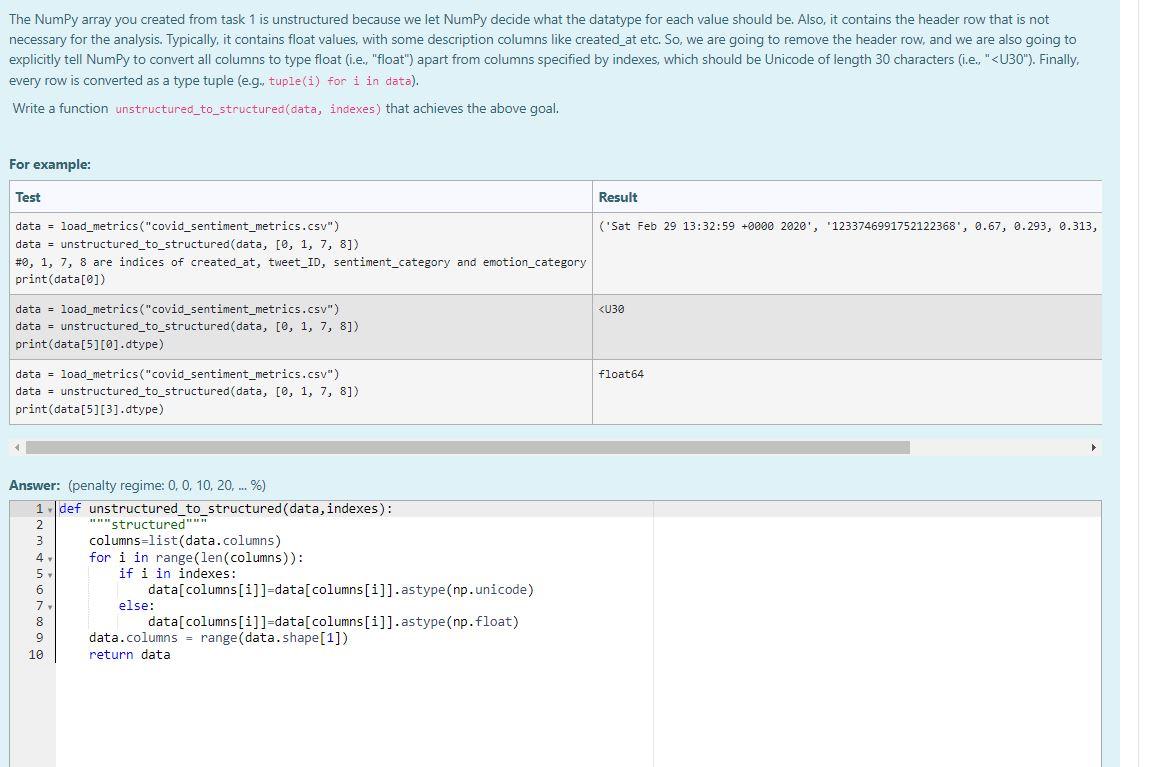
The NumPy array you created from task 1 is unstructured because we let NumPy decide what the datatype for each value should be. Also, it contains the header row that is not necessary for the analysis. Typically, it contains float values, with some description columns like created_at etc. So, we are going to remove the header row, and we are also going to explicitly tell NumPy to convert all columns to type float (i.e., "float") apart from columns specified by indexes, which should be Unicode of length 30 characters (i.e., "<U30"). Finally, every row is converted as a type tuple (e.g., tuple(i) for i in data). Write a function unstructured_to_structured (data, indexes) that achieves the above goal. For example: Test Result data = load_metrics ("covid_sentiment_metrics.csv") ('Sat Feb 29 13:32:59 +0000 2020', '1233746991752122368, 0.67, 0.293, 0.313, data = unstructured_to_structured (data, [0, 1, 7, 8]) # 0, 1, 7, 8 are indices of created_at, tweet_ID, sentiment_category and emotion_category print (data[0]) data = load_metrics ("covid_sentiment_metrics.csv") <U30 data = unstructured_to_structured (data, [0, 1, 7, 8]) print (data[5][0].dtype) data = load_metrics ("covid_sentiment_metrics.csv") float64 data = unstructured_to_structured (data, [0, 1, 7, 8]) print (data[5][3].dtype) Answer: (penalty regime: 0, 0, 10, 20, ... %) 1 def unstructured_to_structured (data, indexes): """structured" 2 columns=list (data.columns) for i in range (len (columns)): if i in indexes: data[columns
]-data[columns].astype else: data[columns]-data[columns].astype data.columns = range (data.shape [1]) return data 3 4 8 9 10 (np.unicode) (np. float)