Page 1 of 1
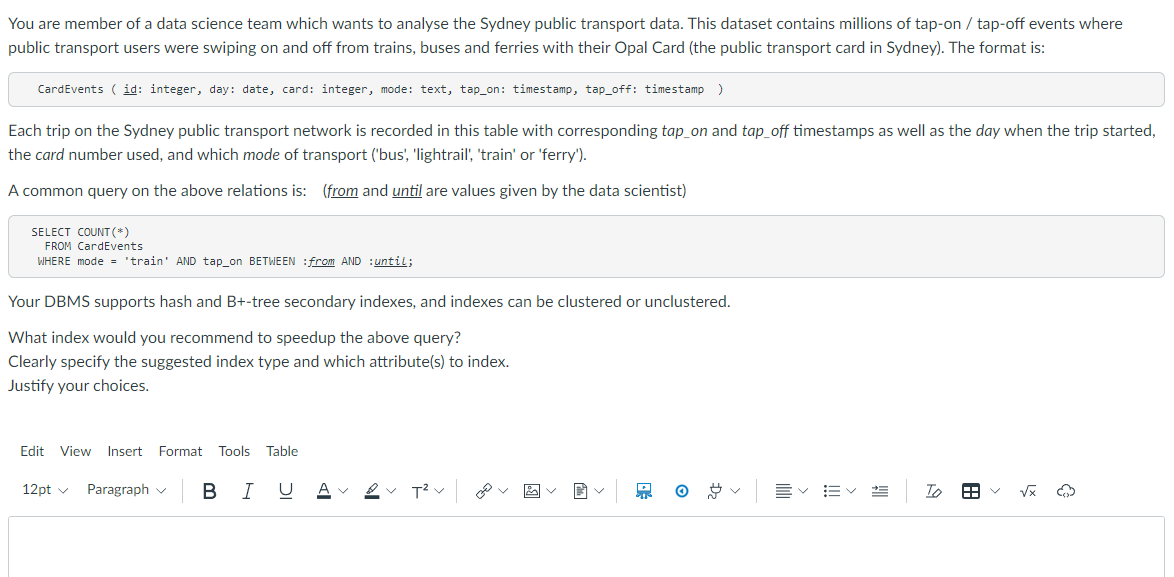
You are member of a data science team which wants to analyse the Sydney public transport data. This dataset contains mil
Posted: Mon Jun 06, 2022 5:54 pm
by answerhappygod
- You Are Member Of A Data Science Team Which Wants To Analyse The Sydney Public Transport Data This Dataset Contains Mil 1 (69.08 KiB) Viewed 30 times
You are member of a data science team which wants to analyse the Sydney public transport data. This dataset contains millions of tap-on / tap-off events where public transport users were swiping on and off from trains, buses and ferries with their Opal Card (the public transport card in Sydney). The format is: CardEvents (id: integer, day: date, card: integer, mode: text, tap_on: timestamp, tap_off: timestamp) Each trip on the Sydney public transport network is recorded in this table with corresponding tap_on and tap_off timestamps as well as the day when the trip started, the card number used, and which mode of transport ('bus', 'lightrail', 'train' or 'ferry'). A common query on the above relations is: (from and until are values given by the data scientist) SELECT COUNT(*) FROM CardEvents WHERE mode = 'train' AND tap_on BETWEEN :from AND :until; Your DBMS supports hash and B+-tree secondary indexes, and indexes can be clustered or unclustered. What index would you recommend to speedup the above query? Clearly specify the suggested index type and which attribute(s) to index. Justify your choices. Edit View Insert Format Tools Table 12pt ✓ Paragraph ✓ B I U DV T² V O To 田く √x A با هم ا B €0 EV EV