
- Your Task We Have Learned How To Implement K Nearest Neighbors Algorithm In Class Now You Are Asked To Write Weighted 1 (64.4 KiB) Viewed 33 times
- Your Task We Have Learned How To Implement K Nearest Neighbors Algorithm In Class Now You Are Asked To Write Weighted 2 (33.2 KiB) Viewed 33 times
Your task: We have learned how to implement K-nearest neighbors algorithm in class. Now, you are asked to write weighted k-nearest neighbors algorithm. Note that, in KNN, a point x is assigned to the class most present among the K points in the training set nearest to x. On the contrary, with the Weighted KNN every neighbor has an associated weight; in the final decision, each neighbor counts with its own weight and the class with the highest weighted sum is chosen. For instance, in the example below (see figure), x is assigned to circle with KNN (K-3), since the most occurring class around x is circle, however, with weighted KNN (K-3), we sum the weights of the nearest K neighboring points for each class and since the sum of weights of squares (0.9) is larger than the sum of weights of circles (0.3+0.5-0.8), x is assigned to square. O ■X 0.9 O 0 class(x) ...O class(x)...> (a) (b) The weights of every neighboring K points are chosen as the 1/Euclidean distances of the training points to the test point x. Wn.d(x,n) where n, is one of the neighboring points and d(x, n) is the Euclidean distance between these two points. In other words, the farther the point, the less weight it has. I Function Parameters: train: This is the training data set used to train your model. Read it as a pandas dataframe. Note that you should not further split the training set as the training set and test set are given separately. test: This is the test data set used to make predictions and test the performance of your model. Read it as a pandas dataframe. Please note that test data set should not be used during the training of the model and only be used to make predictions and compute the accuracy. number_neighbors: Number of neighbors (k) Function Outputs: Predictions: Your function should return class predictions for the test set and type of predictions should be a numpy array. Accuracy: You should also report overall accuracy of your model in the test set. The type of the reported accuracy should be a numpy float. Instructions: A train data set is provided as HW6Train.csv and a test data is provided as HW6Test.csv, also a sample solution is given below. Please use the template uploaded to the Ninova, read the comments in the template and strictly follow the instructions. Do the necessary testing of your function in a python file other than the python file your function is written 00 0.5
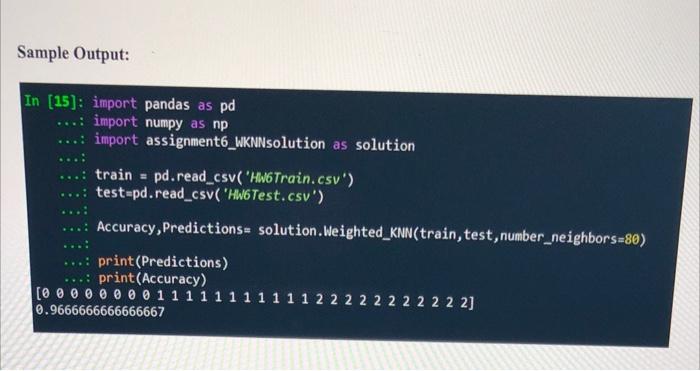
Sample Output: In [15]: import pandas as pd ...: import numpy as np ..: import assignment6_WKNNsolution as solution train = pd.read_csv('HW6Train.csv') test-pd.read_csv('HW6Test.csv') Accuracy, Predictions= solution.Weighted_KNN (train, test, number_neighbors=80) ...: print (Predictions) ...: print (Accuracy) [0 0 0 0 0 0 0 0 1 1 1 1 1 1 1: 0.9666666666666667 222]